ASCII
A tabela de código ASCII (American Standard Code for InformationInterchange) surgiu, nos anos
60, devido a necessidade de criar um padrão que fosse utilizado por todos os
computadores, tornando mais fácil a comunicação entre eles e a troca de dados.
A tabela ASCII utiliza conjuntos de
7 bits para representar 128 caracteres , muitos deles adequados apenas à língua
inglesa, por ter sido desenvolvida nos EUA.
A ISO ( International Standards Organization) adoptou o código
ASCII como norma internacional, com a designação ISO 646, e ampliou-o, passando
a incluir um conjunto de outros idiomas. Para conseguir esta ampliação tiveram
de ser utilizados conjuntos de 8 bits 81byte), permitindo representar 256
caracteres, ou seja, aos 128 caracteres iniciais foram acrescentados mais 128.
No entanto, estes 256 caracteres continuavam a ser insuficientes para englobar
todos os caracteres dos vários idiomas, sendo, por isso, necessário criar
variantes regionais.
Através da norma ISO 8859, foram
normalizados os conjuntos de caracteres de 8 bits, agrupando as variantes de
idiomas relacionados geograficamente. Esta norma é constítuida por várias
partes, desde o ISO 8859-1 até à ISO 8859-10, destinadas aos diversos idiomas,
tais como: ISO 8859-1, conhecida por ISO Latin1 para a maioria dos países da
Europa Ocidental, ISO 8859-8 para o Hebreu e ISO 8859-7 para o Grego moderno.
A norma ISO 8859 não pode ser
considerada uma norma universal devido às limitações que apresenta na
representação, em simultâneo, dos caracteres dos vários idiomas. Para resolver
este problema a ISO introduziu em 1991 a norma ISO 10646 com 32 bits, representando
4 294 967 296 caracteres diferentes.
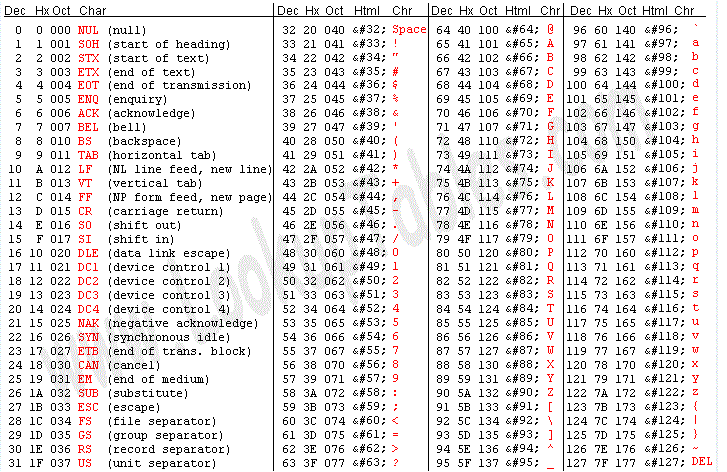 |
| Figura 1 - Tabela ASCII |
Unicode
O Unicode é também um código que define todos os caracteres da maior parte das línguas do Mundo. foi desenvolvido, em simultâneo, por um consórcio industrial, incluindo, entre outras companhias, a Apple, a Adobe, a Microsoft, a HP, a IBM, a Grae/e, a SAP, a SUN e a Unisys. Permite utilizar conjuntos até 4 bytes (32 bits) para codificar os caracteres, sendo mais extenso que a tabela de código ASCII.
Os códigos disponibilizados pela Unicode
permitem representar os caracteres utilizados pelos idiomas modernos e as
formas clássicas de alguns idiomas. Codificam, entre outras, caracteres
acentuados, símbolos de pontuação, símbolos técnicos e matemáticos e outros
símbolos gráficos também conhecidos por dingbats ( por exemplo, estrelas e
outras formas).
Actualmente é promovido e
desenvolvido pela Unicode Consortium, uma organização sem fins
lucrativos que coordena o padrão, e que possui a meta de eventualmente
substituir esquemas de codificação de caracteres existentes pelo Unicode e
pelos esquemas padronizados de transformação Unicode (chamado Unicode
Transformation Format, ou UTF). O seu desenvolvimento é feito em conjunto
com a Organização Internacional para Padronização (ISO) e compartilha
o repertório de caracteres com oISO/IEC 10646: o Conjunto Universal de
Caracteres (UCS). Ambos funcionam equivalentemente como codificadores de
caracteres, mas o padrão Unicode fornece muito mais informação para
implementadores, cobrindo em detalhes tópicos como ordenação
alfabética e visualização.
O seu sucesso em unificar conjuntos de caracteres levou a um uso amplo e predominante na internacionalização e localização de programas de computador. O padrão foi implementado em várias tecnologias recentes, incluindo XML, Java e sistemas operacionais modernos.
O seu sucesso em unificar conjuntos de caracteres levou a um uso amplo e predominante na internacionalização e localização de programas de computador. O padrão foi implementado em várias tecnologias recentes, incluindo XML, Java e sistemas operacionais modernos.
 |
| Figura 2 - Tabela Unicode |
Webgrafia:
https://pt.wikipedia.org/wiki/Unicode
www.google.pt/images
https://pt.wikipedia.org/wiki/ASCII
http://www.asciitable.com/
Sem comentários:
Enviar um comentário